
 Redis
Redis
# 概述
REmote DIctionary Server(Redis) 是一个由 Salvatore Sanfilippo 写的 key-value 存储系统,是跨平台的非关系型数据库
Redis 是一个开源的使用 ANSI C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 API
Redis 通常被称为数据结构服务器
# 安装&应用
# 安装
大致步骤 :
- 安装依赖 gcc
- 上传安装包 , 并解压
- 进入redis根目录 , 运行编译
- 检查成功
- 启动
官方下载 : https://redis.io/download/
安装依赖
Redis是基于C语言运行 , 因此依赖 gcc
yum install -y gcc tcl
上传并解压
# 上传位置自选
/usr/local/src
# 解压 (注意自己的版本
tar -xzf redis-6.2.6.tar.gz
编译运行
# 进入目录
cd redis-6.2.6
# 编译运行
make && make install
检查成功
# 查看环境变量 (看见reids相关配置即可)
ll /usr/local/bin/
该目录以及默认配置到环境变量 , 配置环境后 , 可在任意路径执行命令 .
| 指令集 | 说明 |
|---|---|
| redis-cli | 提供的命令行客户端 |
| redis-server | 服务端启动脚本 |
| redis-sentinel | 哨兵启动脚本 |
# 启动
启动方式有多种 :
- 默认启动 (不建议)
- 指定配置启动
- 开机自启
默认启动
通过命令 直接启动Redis:
redis-server
提示
该启动方式 , 会阻塞会话窗口 , 需要手动关闭窗口
指定配置启动
通过指定配置文件进行启动Redids , 通过 Reids根路径的reids.conf配置文件进行操作
配置启动 点击展开
进入Reids根路径
拷贝备份(防止误操作)
cp redis.conf redis.conf.bckvim进入配置
# 进入 vim reids.conf配置内容 , 使用 Vim查询 更改/添加内容
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0 bind 0.0.0.0 # 守护进程,修改为yes后即可后台运行 daemonize yes # 密码,设置后访问Redis必须输入密码 requirepass 123123启动 , 进入文件根目录 指定文件运行 / 全限定名路径也可以
redis-server redis.conf关闭Redis服务
# 因为之前配置了密码,因此需要通过 -user 来指定密码 redis-cli --user 123123 shutdown
开机启动
默认情况是没有systemctl命令 , 因此我们需要手动配置
开机启动 点击展开
创建系统文件
vim /etc/systemd/system/redis.service配置以下内容 (注意自己的安装路径 , 启动配置文件的路径)
[Unit] Description=redis-server After=network.target [Service] Type=forking ExecStart=/usr/local/bin/redis-server /usr/local/src/redis-6.2.6/redis.conf PrivateTmp=true [Install] WantedBy=multi-user.target通过
systemctl进程 控制# 启动 systemctl start redis # 停止 systemctl stop redis # 重启 systemctl restart redis # 查看状态 systemctl status redis设置开机启动
systemctl enable redis
注意
云服务器 , 需要开启安全组连接端口 : 6379
虚拟机 , 需要 防火墙开端口6379/关闭防火墙
# 终端连接
Redis连接通过 redis-cli命令 :
# reids-cli [options] [commonds]
reids-cli -h 127.0.0.1 -p 6379
| 选项 | 默认值 | 说明 |
|---|---|---|
| -h | 127.0.0.1 | 指定IP |
| -p | 6379 | Reids端口 |
进入Redis命令控制台后 , 需要登录
# AUTH [username] password
# 无账号密码登录
AUTH 123123
# 图形化工具
QuickReids : https://quick123.net/ (opens new window)
开箱即用
# Redis基础
# 数据类型
Redis支持五种数据类型:
- string(字符串)
- hash(哈希)
- list(列表)
- set(集合)
- zset/sortedSet(有序集合)
| 数据类型 | 数据类型存储的值 | 说明 |
|---|---|---|
| String(字符串) | 字符串、整数、浮点数 | 字符串增加 ; 求字符串整数、浮点数 计算 自增/自减.. (最大空间512m) |
| List(列表) | 链表、每个节点都含有一个字符串 | 支持 链表头尾 插入弹出 偏移剪切 查询、删除 指定节点 |
| Set(集合) | 集合中的每个元素都是一个字符串,且他们都是唯一的 | 可 增删查 元素,检测元素是否存在集合 计算集合 交、并、差集 等 随机读取元素 |
| SortedSet(集合) | 可排序Set集合 每个元素都携带 score属性 | |
| Hash(哈希散列表) | Java中的 Map类 ,<K , V> | 可 增删改查 键值对可获取所有键值对 |
| Zset(有序集合) | 有序集合,每个元素都携带score属性 , 元素基于该属性排序 | 可 增删改查 元素 根据分值范围或成员 获取对应元素 |
| HyperLogLog(基数) | 计算重复的值,确定存储数量 | 只提供基数运算,不提供返回功能 |
# 常用命令
Redis 命令用于在 redis 服务上执行操作
命令参考 :
基本类型操作
| 说明 | 命令 |
|---|---|
| 赋值 (key存在覆盖) | SET key value |
| 取值 | GET key |
| 批量赋值 | MSET key value [key value] |
| 批量取值 | MGET key [key] |
| NX 赋值 (key存在跳过 , 不会覆盖) | SETNX key value |
| NX 赋值 并且设置 生存时间 | SETEX key seconds value |
| 字符串数值操作 | |
| 自增+1 | INCR key |
| 自减-1 | DECR key |
| 指定增加 increment | INCRBY key increment |
| 指定减少 decrem | DECRBY key decrem |
| 浮点型自增 increment | INCRBYFLOAT key increment |
| Hash散列 | |
| Hash赋值 (field存在覆盖) | HSET key field value |
| Hash取值 | HGET key field |
| Hash多赋值 | HMSET key field value [field value] |
| Hash批取值 | HMGET key field [field] |
| 获取指定Hash所有信息 | HGETALL key |
| 获取指定Hash中所有field | HKEYS key |
| 获取指定Hash中所有value | HVALS key |
| 自增指定Hash中field的值自增increment | HINCRBY key field increment |
| Hash复制 (field存在跳过 , 不会覆盖) | HSETNX key field value |
| List队列 | |
| 列表左增 | LPUSH key value [value] |
| 列表左弹 | LPOP key |
| 列表右增 | RPUSH key value [value] |
| 列表右弹 | RPOP key |
| 列表总数 | LLEN key |
| 查列表从start 到 stop | LRANGE key start stop |
| Set集合(无序不可重复) | |
| 添加元素 | SADD key member [menber] |
| 删除元素 | SREM key member [member] |
| 获取Set所有个数 | SCARD key |
| 获取Set所有元素 | SMEMBERS key |
| 查 多个集合的交集 | SINTER key [key] |
| 查 元素 是否存在集合 | SISMEMBER key member |
| Zset有序集合(可排序,唯一性) | |
| 添加元素 | ZADD key score member [score member] |
| 获取元素score值 | ZSCORE key member |
| 获取元素在zSet排名 | ZRANK key member |
| 获取zSet所有个数 | ZCARD key |
| 获取zSet指定范围元素个数 | ZCOUNT key min max |
| 获取指定 个数 范围并排序 | ZRANGE key min max |
| 获取指定 score 范围并排序 | ZRANGEBYSCORE key min max |
| ZREVRANGEBYSCORE | |
| 自增指定member中score的值自增 increment | ZINCRBY key increment member |
| 删除元素 | ZREM key member [menber] |
| HyoperLogLog命令 | |
| 添加元素 | PFADD key element [element] |
| 获取指定 HyperLogLog 基数估算值 | PFCOUNT key [key] |
| 将多个 HyperLogLog 合并为一个 HyperLogLog | PFMERGE destkey sourcekey [sourcekey] |
| 生命周期 | |
| 设置key生存周期(秒) | EXPIRE key seconds |
| 查看剩下生存时间TTL | TTL key |
| 清除生存时间 | PERSIST key |
| 其他命令 | |
| 查所有key | KEYS * |
| 查所有以user开头的key | KEYS user * |
| 查看指定key有多大 | MEMORY USAGE key |
| 确认key是否存在(ruturn 0/1 => falet/ture) | EXISTS key |
| 删除key | DEL key |
| 重命名key | RENAME oldkey newkey |
| 获取key值类型 | TYPE key |
| 获取服务器信息 | INFO |
| key移动至指定数据库 | MOVE key db |
| 切换数据库 | SELECT index |
| 停止服务器 | SHUTDOWN |
| 关闭服务连接 | QUIT |
| 删除当前数据库中的所有key | FLUSHDB |
| 删除所有数据库中的所有 | FLUSHALL |
| 获取配置 | CONFIG GET <配置名> |
| 更改配置 (动态配置 , 重启消失) | CONFIG SET <配置名> |
HyoperLogLog命令
随机化的算法,以少量内存提供集合唯一的元素数量的近似值
可接受多个元素作为输入,并给出输入元素的基数估算值
注意
基数:集合中不同元素的数量。 例如{'Sanscan','Bobo','Sanscan','Tomy','Sanscan'}的基数为3
估算值:算法给出的基数并非精确,有些许偏差,但 会控制在范围内
# Java实现
# Jedis
Jedis 是用于Reids命令的Java客户端库 , 命令通常以方法名使用 . 使用简单快速 , 含有线程安全问题
GitHub : https://github.com/redis/jedis (opens new window)
大致步骤 :
- 引入依赖
- 实例jedis对象(连接)
- 使用jedis(操作)
- 释放资源
依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
连接服务器
连接可直接通过 实例Jedis类即可食用
Jedis jedis=new Jedis("192.168.197.129",6379);
// 如果 Redis 服务设置了密码,需要下面这行,没有就不需要
// jedis.auth("123456");
jedis.set("java001","java工程师");
String java001 = jedis.get("java001");
System.out.println(java001);
if(jedis != null){
jedis.close();
}
提示
指令和方法名称类似 , 可以根据命令传参即可使用
# Jedis连接池
jedis 本身线程不安全 , 频繁 创建/销毁 会产生性能损耗 , 使用Jedis连接池替代Jedis直连方式!
大致步骤 :
- 实例连接池 , 并设置基本参数
- 实例 JedisPool连接池对象
- 通过
getResource()方法 提取食用 jedis - 释放资源
JedisPool构造方法重载多种 , 自行API
代码示例 :
代码示例 点击展开
public class ConnectionTest {
public static void main(String[] args) {
JedisPoolConfig config = new JedisPoolConfig();
//最大连接数
config.setMaxTotal(30);
//最大空闲数
config.setMaxIdle(10);
//获取连接池
JedisPool jedisPool = new JedisPool(config,"192.168.74.131",6379);
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
jedis.set("name","张三");
String name = jedis.get("name");
System.out.println("name : " + name);
} catch (Exception e) {
e.printStackTrace();
}finally {
if (jedis != null) {
jedis.close();
}
if (jedisPool != null) {
jedisPool.close();
}
}
}
}
# 集群
PS:如果redis重启,需要将redis中生成的dump.rdb和nodes.conf文件删除,然后再重启
代码展开
public class Demo {
public static void main(String[] args) {
// 创建连接
Set<HostAndPort> nodes = new HashSet<HostAndPort>();
nodes.add(new HostAndPort("192.168.74.131",7001));
nodes.add(new HostAndPort("192.168.74.131",7002));
nodes.add(new HostAndPort("192.168.74.131",7003));
nodes.add(new HostAndPort("192.168.74.131",7004));
nodes.add(new HostAndPort("192.168.74.131",7005));
nodes.add(new HostAndPort("192.168.74.131",7006));
// 集群搭建
JedisCluster cluster = null;
cluster = new JedisCluster(nodes);
// 执行JedisCluster对象中的方法,方法和redis指令一一对应
cluster.set("name","柏竹");
String name = cluster.get("name");
System.out.println("name : " + name);
//存储List数据到列表中
cluster.lpush("site-list", "java");
cluster.lpush("site-list", "c");
cluster.lpush("site-list", "mysql");
List<String> stringList = cluster.lrange("site-list",0,2);
System.out.println("=============");
for (String s : stringList) {
System.out.println(s);
}
//关闭集群 JedisCluster对象
try {
if (cluster != null) {
cluster.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
System.out.println("集群测试完成!!!");
}
}
}
# SpringDataRedis
SpringData是Spring中数据操作的模块 , 该模块集成了很多数据库操作 , 其中也包括 Reids
官方 : https://spring.io/projects/spring-data-redis/ (opens new window)
优点 :
- 整合了 Lettuce 和 jedis
- 提供 ReidsTemplate统一API操作
- 支持 同步/异步/响应式编程
- 线程安全
- 支持 哨兵模式/集群/管道 模式
- 支持 发布订阅模型
- 支持基于 JDK/JSON/字符串/Spring 对象的 序列化/反序列化
SpringDataRedis提供RedisTemplate工具类 , 里面封装了各种Reids操作功能 , 分别介绍 :
| 返回 | API | 说明 |
|---|---|---|
| ValueOperations | redisTemplate.opsForValue() | 操作String类型 |
| HashOperations | redisTemplate.opsForHash() | 操作Hash类型 |
| ListOperations | redisTemplate.opsForList() | 操作List类型 |
| SetOperations | redisTemplate.opsForSet() | 操作Set类型 |
| ZSetOperations | redisTemplate.opsForZSet() | 操作SortedSet类型 |
大致步骤 :
- 引入依赖
- 配置参数
- 配置类配置
- CRUD测试
代码示例 点击展开
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置Reids基本参数
# redis 配置 (端口/地址/密码/连接池配置)
spring:
data:
redis:
port: 6379
host: localhost
password: 123123
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 100ms
我使用的是SprinBoot3.0.4版本 , 旧版本没有data节点
配置类 配置
@Configuration
public class RidesConfig {
/**
* 自定义配置 RedisTemplate
* @param connectionFactory 连接工厂
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 设置 key序列化器 RedisSerializer
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置 连接工厂
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
测试 CRUD
@Resource
private RedisTemplate redisTemplate;
@Test
public void add() {
ValueOperations ops = redisTemplate.opsForValue();
ops.set("String","Sans");
String[] stat = {"zs1","zs2"};
ops.set("List",Arrays.toString(stat));
ops.set("Int",666);
ops.set("double",6.6);
User user = new User();
user.setId(9);
user.setUsername("Sans111");
ops.set("user",user);
}
@Test
public void show() {
ValueOperations ops = redisTemplate.opsForValue();
System.out.println("String =>" + ops.get("String"));
System.out.println("List =>" + ops.get("List"));
System.out.println("Int =>" + ops.get("Int"));
System.out.println("double =>" + ops.get("double"));
System.out.println("user =>" + ops.get("user"));
}
@Test
public void del() {
redisTemplate.delete("String");
redisTemplate.delete("List");
redisTemplate.delete("Int");
redisTemplate.delete("double");
redisTemplate.delete("user");
}
提示
SpringBoot3.02版本以下 , 采用 @Resource注解 自动注入 , 需要添加name参数进行指定名称Bean的方法名称 , 例如 :
@Resource(name="redisTemplate")
private RedisTemplate redisTemplate;
# 自定义序列化器
默认采用的jdk序列化对key和value造成乱码 , 无难以阅读 , 而且乱码在外部获取也不方便 , 因此 需要执行配置序列化
文章参考 :
- https://developer.aliyun.com/article/907866 (opens new window)
- https://developer.aliyun.com/article/907868 (opens new window)
- https://developer.aliyun.com/article/907869 (opens new window)
RedisConfig配置类
@Configuration
public class RidesConfig {
/**
* 自定义配置 RedisTemplate
* @param connectionFactory 连接工厂
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
// 设置 key序列化器 RedisSerializer
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置 连接工厂
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
# Redisson
Redisson是基于 Reids实现的分布式 , 可伸缩Java数据结构集合等类型对象
介绍 : https://github.com/redisson/redisson (opens new window)
版本 : https://github.com/redisson/redisson/tree/master/redisson-spring-boot-starter (opens new window)
高级Sedisson应用 : 传送门跳转
快速入门
快速应用 点击展开
引入依赖
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency>版本迭代快 , 非SprinBoot谨慎选择Redisson版本
写入配置
@Bean public RedissonClient redissonClient() { // 创建配置 Config config = new Config(); String redisAddress = String.format("redis:127.0.0.1:6379"); config.useSingleServer() .setAddress(redisAddress) .setDatabase(0); // 创建实例 RedissonClient redissonClient = Redisson.create(config); return redissonClient; }测试应用
@Resource private RedissonClient redissonClient;@Test public void redissonTest() { // JVM 本地操作 List<Object> list = new ArrayList<>(); list.add("sasn"); System.out.println("list.get(0) = " + list.get(0)); // reids 操作 // RLIST 继承了 List特性 RList<Object> rList = redissonClient.getList("test-list"); rList.add("123123"); System.out.println("rList.get(0) = " + rList.get(0)); // Redisson 其他集合... //redissonClient.getMap("test-map"); }
# 定时任务
意图 : 每天提前更新的缓存数据 , 防止数据在高峰期抢占资源
注意 :
- 线程等待时间为0 , 多个线程只能抢一次
- 释放锁前提需要判断是否是本线程的锁否则跳过
- 释放锁是在 try-catch 中的 finally中进行检查释放 (防止中途代码异常)
示例 :
定时任务采用 Springboot内置 @EnableScheduling 和 采用Redisson分布式锁 实现
多台服务的情况下 , 每天凌晨12点 加载定时任务 , 多个服务只能一个服务进行执行任务 (避免不必要的资源浪费)
代码示例 点击展开
@Resource
private RedissonClient redissonClient;
@Scheduled(cron = "0 0 0 * * *")
public void doCacheRecommendUser() {
RLock lock = redissonClient.getLock("sans:precachejob:docache:lock");
/*
参数
1. 等待获取(0无需等待)
2. 过期时长
3. 时间单位
*/
try {
// 只有一个线程获取到锁
if (lock.tryLock(0, 30000, TimeUnit.MILLISECONDS)) {
System.out.println("lockName op :" + Thread.currentThread().getName());
for (Long userId : mainUserList) {
String redisKey = String.format("sans:user:recommend:%s", userId);
ValueOperations<String, Object> ops = redisTemplate.opsForValue();
QueryWrapper<User> qw = new QueryWrapper<>();
Page<User> userPage = userService.page(new Page<>(1, 20), qw);
try {
ops.set(redisKey, userPage, 1, TimeUnit.DAYS);
} catch (Exception e) {
log.error("redis set key");
}
}
}
} catch (InterruptedException e) {
log.error("doCacheRecommendUser error " + e.getMessage());
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
System.out.println("lockName ed :" + Thread.currentThread().getName());
}
}
}
# 续约锁
监听线程 , 如方法未执行完 , 会帮你重置 reids锁的过期时间
@Autowired
private RedissonClient redisson; //自动装配RedissonClient
RLock lock = redisson.getLock("onelock"); //获取锁
lock.lock(); //加锁
lock.unlock(); //释放锁
主要通过方法 ==lock.tryLock(0, -1, TimeUnit.MILLISECONDS)==
方法参数说明 : 1参数 等待获取锁时长 , 2参数 锁过期时长 , 3参数 时间单位
续约锁需要指定 2参数为 -1 , Redisson自动设为 续约模式 , 直到线程执行完成并释放锁
注意 :
- 过期时间必须定义为 -1
- 监听当前线程 , 默认过期时间为30s , 每 10s 续期一次
- 如果线程挂掉(debug模式也会误认宕机) , 则不会续期
tryLock()方法必须要用try-catch包括并且在finally中进行释放锁(防止异常后能够进行释放锁)
代码示例 :
/**
* 看门狗机制测试
*/
@Test
public void redissonLookDoorDog() {
RLock lock = redissonClient.getLock("sans:precachejob:docache:lock");
System.out.println("start");
try {
if (lock.tryLock(0, -1, TimeUnit.MILLISECONDS)) {
Thread.sleep(300000);
}
} catch (InterruptedException e) {
System.out.println(e.getMessage());
} finally {
// 只能释放本身线程的锁(以防释放其他线程的锁)
if (lock.isHeldByCurrentThread()) lock.unlock();
}
}
# Reids进阶
# 数据结构
# GEO
GEO 是存储 地理坐标 的数据结构 , 基于zSet数据结构实现 , 在Redis3.2版本中支持
常用命令 :
| 命令 | 说明 |
|---|---|
| GEOADD | 添加地理位置 , 经度(longitude) ; 维度(latitude) ; 值(member) |
| GEODLST | 获取 两个点之间的距离(单位: m) |
| GEOHASH | 获取 指定member坐标 转为hash字符串形式 |
| GEOPOS | 获取 member坐标 |
| GEORADIUS | 获取 范围内的member , 指定 圆心 ; 半径 , 找到圆内的所有member , 按距离返回 |
| GEOSEARCH | 获取 指定范围的member , 按照指定范围返回 |
| GEOSEARCHSTORE | 找出位于指定范围内的元素,中心点是由给定的位置元素决定 |
# Bit
BitMap 是基于 字符串 的数据结构 , 能够实现位操作
常用命令 :
| 命令 | 说明 |
|---|---|
| SETBIT | 向指定位置(offset)存入一个0或1 |
| GETBIT | 获取指定位置(offset)的bit值 |
| BITCOUNT | 统计BitMap中值为1的bit位的数量 |
| BITFIELD | 操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值 |
| BITFIELD RO | 获取BitMap中bit数组,并以十进制形式返回 |
| BTOP | 将多个BitMap的结果做位运算(与、或、异或) |
| BITPOS | 查找bit数组中指定范围内第一个0或1出现的位置 |
# HyperLogLog
HyperLogLog(HHL)是一种基数统计算法 , 用于解决海量数据的基数统计问题
优点 :
- 占用内存小(不超过16kb)
- 对添加的元素唯一统计
- PFCOUNT统计误差为 0.81%
常用命令 :
| 命令 | 说明 |
|---|---|
| PFADD | 将任意数量的元素添加到指定的 HyperLogLog (不能重复) |
| PFCOUNT | 统计HyperLogLog数量 |
| PFMERGE | 将多个 HyperLogLog 合并为一个 HyperLogLog (保证唯一) |
# 缓存淘汰
Redis的缓存数据是基于内存存储的 , 内存终究会有不够用的时候 , 为了保证内存不会爆满 , 导致宕机 , 因此 Reids的缓存淘汰机制就起到关键作用
淘汰分类 :
| 内存淘汰 | 超时淘汰 | 主动更新 | |
|---|---|---|---|
| 说明 | Redis内置机制 , 当内存不足时会自动淘汰部分数据 | 数据会根据TTL超时而淘汰 | 自行编写业务逻辑 , 修改数据库更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
对 缓存与数据库 一致性要求高 , 可采取以下方案 :
读数据 :
- 缓存查到直接返回
- 缓存查不到 , 写入缓存 , 并设超时时间
写数据 :
- 先写数据库 , 后删除缓存
- 确保数据库和缓存操作是过程无异常(事务)
# 事务
Redis 事务可以一次执行多个命令, 并且带有以下两个重要的保证:
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客 户端发送来的命令请求所打断
- 事务中的命令要么全部被执行,要么全部都不执行
事务阶段:
- 开始事务
- 命令入队
- 执行事务
事务命令
| 命令 | 描述 |
|---|---|
| MULTI | 开始事务 |
| DISCARD | 取消事务 |
| EXEC | 结束事务 |
# 发布订阅
Redis 发布订阅(pub/sub) 是一种消息通信模式:发布者(pub)发送消息,订阅者(sub)接收消息
但发布者发布消息发送到信道 , 当有消费者订阅信道(频道)channel , 将会接收到发布的相关消息
特点 :
- 可实现广播形式发布消息
- 不能对消息不支持持久化
- 消息堆积有上限 , 超出会丢失
命令 :
| 命令 | 说明 |
|---|---|
| SUBSCRIBE channel [channel] | 订阅 一个/多个 频道 |
| PUBLISH channel message | 发布消息到 信道 |
| PSUBSCRIBE pattern [pattern] | 订阅与pattern格式匹配所有频道 |
pattern参数
字符串 通配符应用 , 支持有以下通配符 :
?: 统配 一个 字符*: 通配 一个/多个 字符[]: 通配 多个常量 . 例如 : h[ae]llo -> hello / hallo 识别两种!
测试:
- 打开3个客户端 , 分别 1个发布者 , 2个订阅者
- 订阅者1 : 订阅 SUBSCRIBE order.q1
- 订阅者2 : 订阅 PSUBSCRIBE order.q?
- 发布者发布 :
- SUBSCRIBE order.q1 msg1
- SUBSCRIBE order.q2 msg2
- 分别查看他们接收情况
# 消息队列
Redis5.0 引入了新数据类型 Stream , 用于实现消息队列
了解即可 , 消息队列还得要学RabbitMQ ~
特点 :
- 消息可回溯 (不会出现读完删除)
- 一个消息可多消费者读取
- 可阻塞读取
- 消息可能会漏读
命令 :
| 命令 | 参数 | 说明 |
|---|---|---|
| XADD key *|ID field value [field value] | ID : 消息唯一id , 如果为 * 代表自动生成(格式 "时间戳-递增数字") field value : 消息对 (类似Hash哈希键值对) | 添加 消息队列 |
| XREAD [COUNT count] [BLOCK milliseconds] STREAMS key ID | COUNT count : 读取最大数 BLOCK milliseconds : 等待时长ms(0永久阻塞) key : 指定队列名称 ID : 起始id开始读取 (0第一个开始 ; $最新消息开始) | 读 消息队列 |
读取方式 :
- 阻塞等待读取最新一条消息 : XREAD BLOCK 0 STREAMS key $
- 读取所有消息(数值越大读越多) : XREAD COUNT 99 STREAMS key 0
# 消费者组
顾名思义 , 就是将多个消费者进行分别组队 , 监听一个队列即可
消息都会有一个状态 pending(表示未读) , 并且存储到 pending-list列表 中等待消费 , 直到 XACK命令 确认该消息完成 , 才会清除 pending-list列表中的指定消息 !
特点 :
- 分流消息(消息分布到组内 , 而不是重复消息)
- 标识消息(标识消息是否已读 , 保证消息读取)
- 确认消息(确认消息清除消息的标识)
命令
# 创建 , 创建消费者组 . ID : 起始id开始读取 (0第一个开始 ; $最新消息开始)
XGROUP CREATE key groupName ID [MKSTREAM]
# 删除 , 指定 消费者组
XGROUP DESTORY key groupName
# 添加 , 指定 消费者组 添加 消费者
XGROUP CREATECONSUMER key groupname consumername
# 删除 , 指定 消费者组 删除指定 消费者
XGROUP DELCONSUMER key groupname consumername
# 读取 , 指定 消费者组中的消费者 的数据(ID可以为 '>' 下一个未消费的消息开始)
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] STREAMS key ID
# 持久化
Redis值放在内存中 , 为防止突然断电等特殊情况的发生 , 需要对数据进行持久化备份 . 即将内存数据保存到硬盘
Reids有两种持久化 :
# RDB持久化
RDB 是采用二进制进行备份文件(数据快照) . 将内存的所有数据保存起来 , 故障修复后读取备份文件
一般情况在特定时间 , 执行备份 , 持久化结束后 , 替换上一次持久化的文件 , 达到更新效果
主动备份文件 在Redis主进程里执行命令 : (数据量大可能会较慢)
| 命令 | 说明 |
|---|---|
save | 主线程备份 , 会阻塞其他命令 |
bgsave | 异步线程备份 |
提示
如果是主动停机 , Redis会自动执行一次 RDB持久化
bgsave运作过程
- 调用 fork() 函数 , 创建 子进程 , 进行备份数据 (此时 子进程和主进程 内存是共享的)
- 备份完后 , 覆盖旧 备份文件
::: nate 读写共存情况
fork采用的是 copy-on-write技术 :
- 当主进程执行 读操作 时 , 访问共享内存
- 当主进程执行 写操作 时 , 则会拷贝一份数据 , 执行写操作
极端情况 : 备份过程 , 如果大量些数据 , 消耗的较高 , 需要提前预留内存!!!
:::
RDB配置
Redis根目录下的 redis.conf文件
# dbfilename:RDB持久化的文件名称
dbfilename dump.rdb
# dir:文件保存的路径(reids根目录)
dir ./
# 快照触发 save 机制
# 900s 内 更变操作1 : 触发save
# 300s 内 更变操作10 : 触发save
# 60s 内 更变操作10000 : 触发save
save 900 1
save 300 10
save 60 10000
# 当 save中途出现异常时 , 是否阻塞客户端 更变操作 (可能因为磁盘 满了/故障 导致异常)
stop-writes-on-bgsave-error yes
# rdbcompression : 是否压缩备份文件(会损耗CPU,不建议启动)
rdbcompression no
# AOF持久化
AOF 是通过 Reids处理写命令后会追加记录在AOF文件 , 可查看的命令日志文件
当需要恢复数据时直接读取AOF文件 , 还原所有的操作过程 , AOF文件内容是字符串 , 便于阅读
AOF配置
Redis根目录下的 redis.conf文件
# appendonly : 启动AOF功能 (默认no)
appendonly yes
# appendfilename : 指定aof文件名称
appendfilename appendonly.aof
# appendfsync : 指定aof操作中文件同步策略
# 三个参数:always/everysec/no (默认everysec)
appendfsync everysec
# todo 在aof-rewrite期间,appendfsync是否暂缓文件同步,"no"表示“不暂缓”,“yes”表示“暂缓”,默认为“no”
no-appendfsync-on-rewrite no
# AOF触发重写 : 超过指定容量 单位mg,gb(默认64mb;建议512mb)
auto-aof-rewrite-min-size 64mb
# AOF触发重写 : 比上次重写超过指定百分比
# 每次触发AOF记录 , 都会检测大小 , 从而进行判断下次重写时机
auto-aof-rewrite-percentage 100
重写机制
手动重写 (Reids执行命令) : bgrewriteaof
假如没有重写机制
当AOF文件读取执行命令时 , 可能会出现对同一个key进行多次写操作 , 但只有最后一次写操作的记录 , 那么前面的写操作则没有意义 . 为此AOF提供了重写机制 , 仅保留最后写key的数据 执行重写后AOF文件是无法阅读的
appendfsync 文件同步策略
| 配置项 | 记录时机 | 优点 | 缺点 | 说明 |
|---|---|---|---|---|
Always | 同步写操作记录 | 可靠 | 性能影响大 ; 频繁IO操作 | 每次执行写命令后立即记录 |
everysec | 每秒记录 | 适中 | 时效性问题 , 最多失去1s数据 | 1秒前写命令的会存储到AOF缓冲区中 , 1秒后将缓冲区数据进行记录 |
no | 操作系统控制 | 最好 | 可靠性差 , 逻辑不好可能丢失数据 | 写命令的会存储到AOF缓冲区中 , 由操作系统决定将缓冲区数据进行记录 |
# RDB与AOF区别
| RDB | AOF | |
|---|---|---|
| 宕机恢复 | 快 | 慢 |
| 容量大小 | 体积小 , 含有压缩 | 体积大 , 时刻记录写命令 |
| 内容可读 | 否 | 是 (重写不可读) |
| 数据结构 | 二进制 | 字符串 |
| 持久化方式 | 快照存储 | 记录存储 |
| 数据完整性 | 不完整 , 两次备份数据会丢失 | 相对完整 , 取决记录方式 |
| 恢复优先级 | 低 , 完整性不如AOF | 高 , 数据完整度相对较高 |
| 资源占用 | 高 , 消耗大量CPU和内存 | 低 , 消耗磁盘IO读写 (重写会消耗CPU和内存) |
| 使用场景 | 灾难性恢复 | 对数据安全性要求较高 |
笔记
RDB与AOF 各有自己的优缺点 , 如果对数据的安全性要求高的情况 , 一般会采用两者结合使用
相信以后会将这两种方案进行统合~
# 主从机制
Redis是指Reids主服务器 , 将数据拷贝到其他Reids从服务器上 , 从而搭建成主从集群 , 实现读写分离
为了更好理解
主服务器
master从服务器
slave/replication
主从复制作用 :
- 故障恢复 : master 发生故障,由 slave 提供服务,直至 master 修复
- 数据冗余 : 实现数据同步备份,持久化之外的数据备份方式
主从复制原理 :
- slave 向 master 发送同步请求 , 携带replid和offset , master 也响应 replid和offset , slave 更新版本信息 (此时会响应OK)
- master 每次触发执行
bgsave后 , 都会建 RDB文件 发送给 slave , slave 接收后会清空内存并加载RDB文件 - 发送记录 master 期间的命令 , 通过
repl_baklog发送到 slave 进行同步指令信息
步骤1 关键字说明
replid : 数据集标记 , 一般用于判断数据集是否一致/第一次同步
offset : 偏移量 , 随着记录 repl_baklog 越来越大 . 需要通过偏移量控制更新范围
实现 :
- 启动Reids两个以上
- 连接 , slave 执行连接命令 以下两个其中一个连接命令
SLAVEOF host port(5.0前版本)SRPLICAOF host port(5.0后版本)
- 验证 , master 查看状态命令
INFO replication
提示
搭建主从思路可以根据不同 ip/端口 进行搭建多个连接应用
注意
- 一旦连接成功 , 自动同步
- slave 只能读不能写 ; master 能读写
- slave 宕机时间不能够久 , 过久可能会导致数据同步不到位
# 哨兵模式
哨兵模式(Sentinel) 是 监视多个Redis服务器的状态 . Sentinel可以有多个 组成Sentinel系统
作用 :
- 系统监控 : 按指定频率PING命令检查 master 和 slave 状态 (默认1s一次)
- 故障修复 : 如果 master 故障 , Sentinel会自选举一个 slave 升为 master , 当故障实例恢复后以新 master 为主(按照权重选举)
- 状态通知 : Sentinel充当Reids实例 , 当集群故障转移 , 会进行一次通知
心跳监控机制
Sentinel每秒会PING检查实例运作状态 , 下线状态有两种可能 : (Sentinel集群状态下)
- 主观下线 : 某个 Sentinel 检测实例未响应 , 视为 客观下线
- 客观下线 : 多个 Sentinel 检测实例未响应 , 且超过指定 quorun值 , 则视为 客观下线
建议 :
quorun值 最好是 Sentinel集群 数量的一般以上
选举机制
Sentinel一旦发现 master 故障 , Sentinel选举一个 slave 升为 master , 选举依据 :
- 排除选举 , 会判断原先的 slave和master 断开时长记录 , 如果超过指定值 (down - after - milliseconds * 10) , 则视为 老旧实例节点(不靠谱) , 进行排除
- 判断 slave 的 slave-priority值(权重) , 越小优先级越高 , 0则不选举 (默认100)
- 如果 slave-priority值 一致的实例 , 那么判断 offset值 , 越大数据越新 , 优先级也就越高
- 判断 slave 运行id的大小 , 越小优先级越高
转移机制
Sentinel选举一个实例作为新的 master 时 , 运作步骤如下 :
- 选举master , 对选中的 slave 发送执行命令
SLAVEOF no noe, 称为 新的 master - 广播其他 slave 发送执行命令
SLAVEOF host port/SLAVEOF host port(指定 新master 的IP和端口) - 旧实例的 master , 会被标记为 slave , 但实例故障恢复后也会执行 步骤2的命令
Redis版本指令更变
SLAVEOF host port(5.0前版本)SRPLICAOF host port(5.0后版本)
实现 :
哨兵代码示例 点击展开
假设节点实例
| 节点实例 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 20001 |
| s2 | 192.168.150.101 | 20002 |
| r1(master) | 192.168.150.101 | 6379 |
| r2(slave) | 192.168.150.101 | 6380 |
| r3(slave) | 192.168.150.101 | 6381 |
创建目录
# 进入/tmp目录 cd /tmp # 创建目录 mkdir s1 s2在 s1 , s2 目录中 , 配置
sentinel.conf文件 (要配置s1和s2)# 当前s1端口 port 20001 # 当前s1 IP地址 sentinel announce-ip 192.168.150.101 # 定义主节点master名为 mymaster(任意) ; IP ; 端口 ; quorun(掉线判断) sentinel monitor mymaster 192.168.150.101 7001 2 # slave与master 断开的 超时时间 sentinel down-after-milliseconds mymaster 5000 # 实例故障恢复的 超时时间 sentinel failover-timeout mymaster 60000 # 工作目录 dir "/tmp/s1"启动 Sentinel哨兵模式
redis-sentinel /tmp/s1/sentinel.conf redis-sentinel /tmp/s2/sentinel.conf # 也可 Reids中的Sentinel配置运行(不用服务器情况下) redis-server redis.conf --sentinel测试 , 保证 s1 , s2 , r1 , r2 , r3 正常运作
- 进程查看
ps -aux|grep redis - 进程消灭 r1(master)
KILL 9 pid(模拟master宕机) - 状态检查
INFO replication, 查看是否转化为 master - 日志检查 Reids根据的
reids.log文件可以查阅(可得知变化的状态)
- 进程查看
# 哨兵RedisTemplate访问
StringBoot中的RedisTemplate底层通过 lettuce实现 对节点的监控和自动切换
代码示例 点击展开
依赖配置
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>配置文件
spring: redis: sentinel: # 指定naster名称 master: mymaster # 指定redis-sentinel集群信息 nodes: - 192.168.150.101:20001 - 192.168.150.101:20002配置类 , 写在Redis配置类即可
@Bean public LettuceclientConfigurationBuilderCustomizer configurationBuilderCustomizer(){ return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); }运行测试即可 , 可以在控制台看见日志情况
需要配置日志依赖 , 用于查阅日志变动情况
在配置类中 , 我们可以看见有 ReadFrom枚举选择 , 读取策略
| ReadFrom枚举 | 说明 |
|---|---|
| MASTER | 从 master 读取 |
| MASTER_PREFERRED | 优先从 master 读取 , 不可用才读取 slave |
| REPLICA | 从 slave 读取 |
| REPLICA_PREFERRED | 优先从 slave 读取 , 不可用才读取 master (建议) |
# 集群
Redis集群是由一个以上的多个实例节点组成的分布式服务器 , 解决了 高并发/高可用/稳定高 问题
优点 :
- 将数据 自动切分(slot) 到多个节点的能力
- 部分实例节点宕机 , 仍然保持通信应用 , 无需哨兵 , 自带主从切换
redis-cluste集群方案
Redis-Cluster采用无中心结构 , 每个节点保存数据和整个集群状态 , 每个节点都和其他所有节点连接
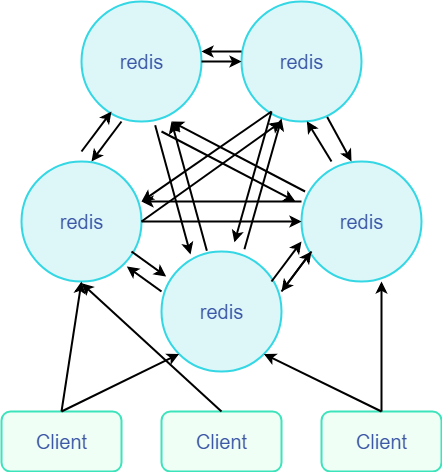
结构/特点 说明
- 所有redis节点都是彼此互联 , 且每个Reids都是 master . 内部使用二进制协议优化传输速率
- 所有reids之间通过 PING命令 检测彼此健康状态
- client 与 redis节点是直连的 , 无需中间层 , client 只需连接任意一个redis节点即可应用
- 当 Redis集群 任意 master 宕机 , 且当前 master 没有 slave , 则 Redis-Cluster 为 fail 状态 (但 slot映射 不完全进入 fail状态)
- 当 Redis-Cluster 中 master 挂掉一半以上 , 则 Redis-Cluster 为 fail 状态
# 集群搭建
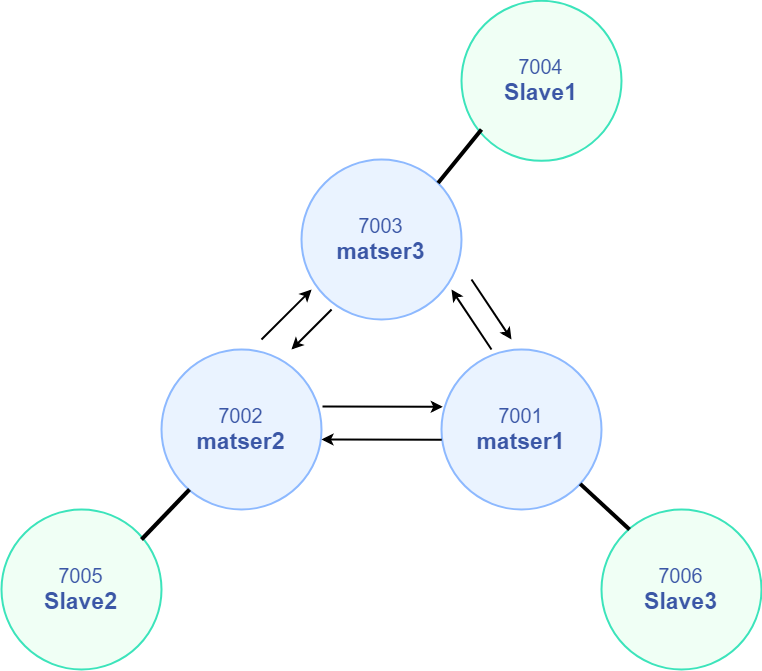
节点实例 :
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 7004 | slave |
| 192.168.150.101 | 7005 | slave |
| 192.168.150.101 | 7006 | slave |
结构图 :
步骤 :
代码示例 点击展开
新建集群目录
# 进入/tmp目录 cd /tmp # 创建目录 mkdir 7001 7002 7003 7004 7005 7006在 /tmp 创建一个新的
redis.confport 6379 # 开启集群功能 cluster-enabled yes # 集群的配置文件名称,不需要我们创建,由redis自己维护 cluster-config-file /tmp/6379/nodes.conf # 节点心跳失败的超时时间 cluster-node-timeout 5000 # 持久化文件存放目录 dir /tmp/6379 # 绑定地址 bind 0.0.0.0 # 让redis后台运行 daemonize yes # 注册的实例ip replica-announce-ip 192.168.150.101 # 保护模式 protected-mode no # 数据库数量 databases 1 # 日志 logfile /tmp/6379/run.log拷贝 到节点目录并批更改 (配置自行检查进入下一步)
# 进入/tmp目录 cd /tmp # 执行拷贝 echo 7001 7002 7003 7004 7005 7006 | xargs -t -n 1 cp redis.conf # 更改配置 printf '%s\n' 7001 7002 7003 7004 7005 7006 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf一键启动所有服务
printf '%s\n' 7001 7002 7003 7004 7005 7006 | xargs -I{} -t redis-server {}/redis.conf集群检查 ,
ps -ef | grep redis观察端口运行状态信息集群连接 , 通过
redis-cli --cluster命令搭建集群 (5.0以上版本)redis-cli --cluster create --cluster-replicas 1 \ 192.168.150.101:7001 \ 192.168.150.101:7002 \ 192.168.150.101:7003 \ 192.168.150.101:7004 \ 192.168.150.101:7005 \ 192.168.150.101:7006 \集群查看
redis-cli -p 7001 cluster nodes测试... . 集群进入操作时命令需要加上
-credis-cli -c -p 7001一键关闭
# 进入/tmp目录 cd /tmp printf '%s\n' 7001 7002 7003 7004 7005 7006 | xargs -I{} -t redis-cli -p {} shutdown
步骤6的参数说明 :
| 参数/指令 | 说明 |
|---|---|
| redis-cli --cluster | 集群指令 |
| create | 创建集群 |
| --cluster-replicas n | 根据 节点总数 ÷ (n+1) 得到master的数量 , 节点列表中的前 n 个就为 master , 其余的为 slave |
新增实例节点
点击展开
添加新的 master : redis-cli --cluster add-node new_host:new_port existing_host:existing_port
加入集群 , 添加新实例节点 master 7007 . 后面的旧实例作为通知引用
# 在以上集群基础上添加实例节点 redis-cli --cluster add-node 192.168.150.101:7007 192.168.150.101:7001分配slot , 将7001 插槽分配给 7007 , 7007加入集群是没有插槽分配的(没有插槽等同于没有集群效果)
# 先查看节点 id/插槽量 , 记录他们的 集群节点的id redis-cli -p 7001 cluster nodes # 指定实例分配插槽 redis-cli --cluster reshard 192.168.150.101:7001 # 1询问 : 你需要分配多少插槽 : 3000 # 2询问 : 谁进行接受插槽分配 : 7004的节点id # 3询问 : 从哪数据源进行拷贝 : 7001的节点id => done完成测试即可
添加新的 slave : redis-cli --cluster --cluster-slave --cluster-master-id <arg> new_host:new_port existing_host:existing_port
# 先查看节点 id/插槽量 , 记录他们的 集群节点的id
redis-cli -p 7001 cluster nodes
# 将 7007 作为 7001 的 slave
redis-cli --cluster --cluster-slave --cluster-master-id {7001节点Id} 192.168.150.101:7007 192.168.150.101:7001
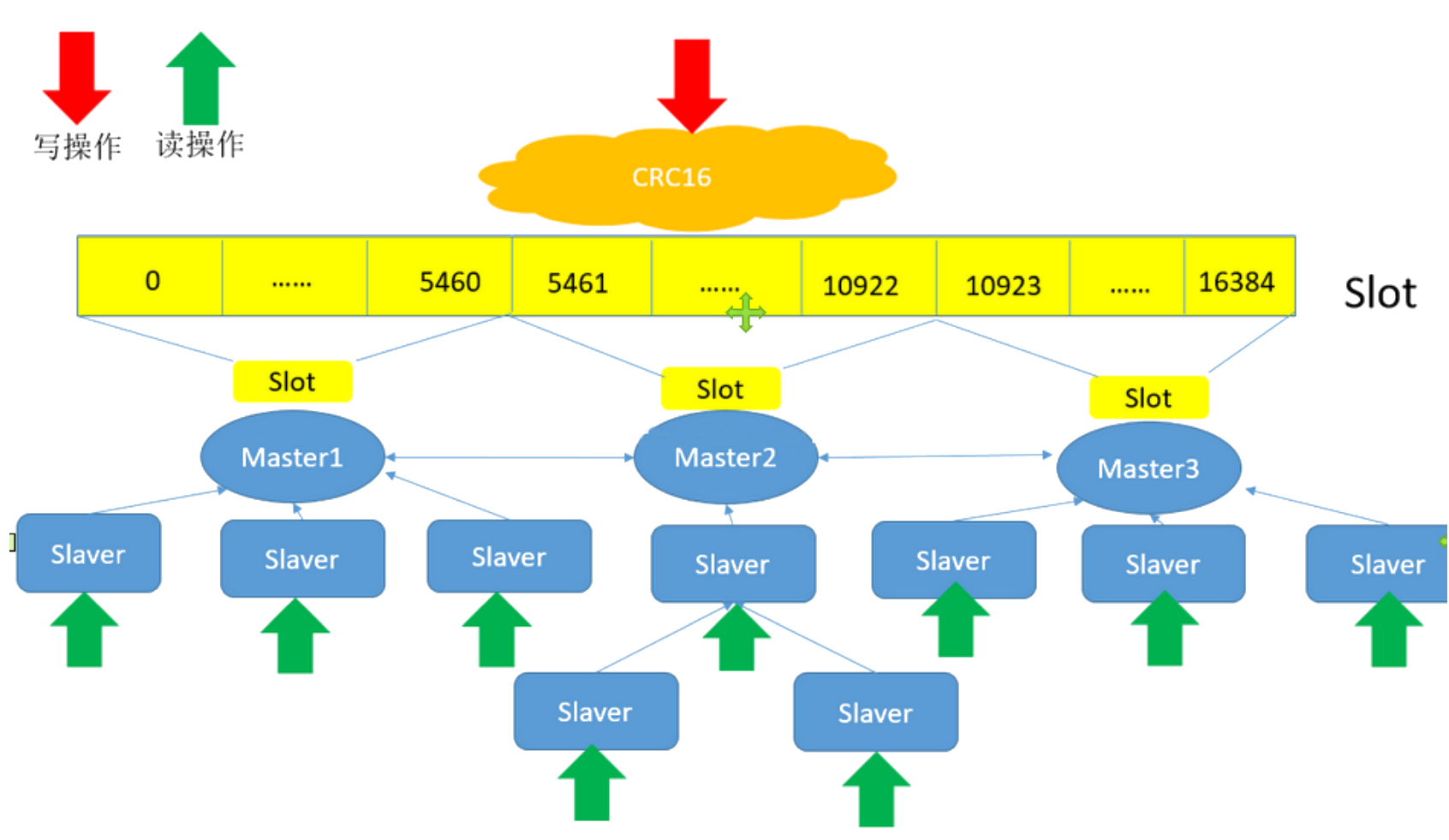
# 散列插槽slot
Redis集群 采用虚拟哈希插槽分区(hash slot) , 将写入的 Key 计算得到需要映射的slot , slot映射一共有 [0-16383] 个 , 这些slot会分配到每个 master节点上 , 从而实现分工合作
映射求余计算公式 : slot = CRC16(key) & 16383
观察slot节点分配 : redis-cli -p 7001 cluster nodes
控制key存到指定slot
可以通过写命令的 key前缀加上 {typeId} 即可实现 , 例如 : set {a}num 123
slot映射 结构图 :
# 集群RedisTemplate访问
StringBoot中的RedisTemplate底层通过 lettuce实现 对集群监控等支持
代码示例 点击展开
引入依赖
配置文件 , 配置地址
spring: redis: cluster: # 指定集群 nodes: - 192.168.150.101:7001 - 192.168.150.101:7002 - 192.168.150.101:7003 - 192.168.150.101:7004 - 192.168.150.101:7005 - 192.168.150.101:7006Redis配置类 , 配置读写分离
@Bean public LettuceclientConfigurationBuilderCustomizer configurationBuilderCustomizer(){ return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); }运行测试即可 , 可以在控制台看见日志情况
需要配置日志依赖 , 用于查阅日志变动情况
# 分布式锁
分布式锁是多个服务器在同一系统中可服务器多个进程对资源的访问
Redis为单进程 单线程模式 , 采用队列模式将并发访问变成串行访问 , 且多客户端对Redis的连接并不存在竞争 关系。redis也可实现分布式锁
意图 : 节省资源空间
应用满足条件
- 系统是一个分布式的系统
- 资源共享 (各个系统访问同一数据库)
- 同步访问 (多个进程同时访问同一个资源)
redis分布式锁命令
SETNX ==SETNX key value== key存在 , 不做操作 ; key不存在则设值
GETSET ==GETSET key value== 先获取key对应的旧值 , 且新值覆盖替换旧值
注意
- 用完锁一定要释放
- 锁一定要加过期时间
# 多级缓存
多级缓存架构图 :
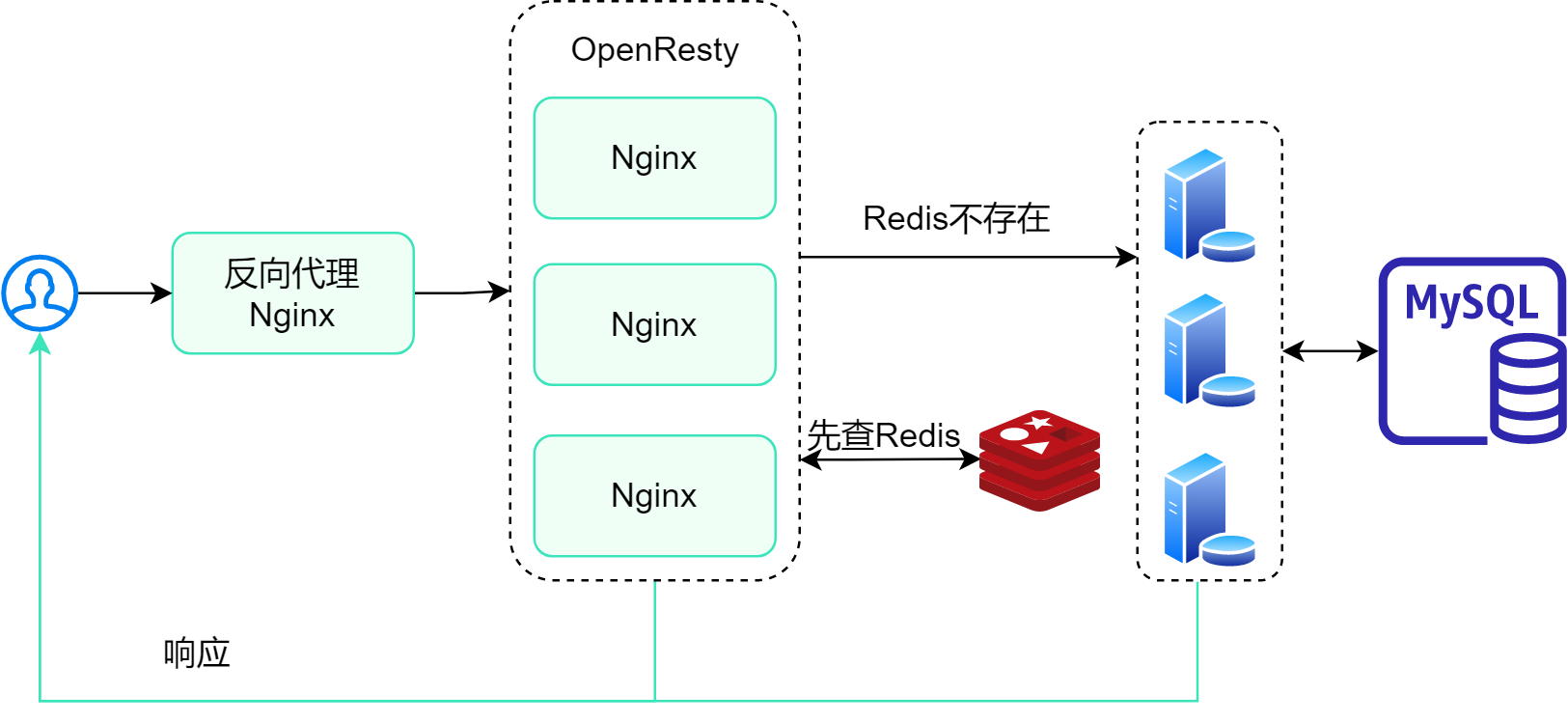
多层缓存 , 分别说明缓存层级 : (可以根据情况优化)
- OpenResty Nginx 字典 本地缓存
- Redis缓存
- JVM缓存 (集群需要依赖 负载均衡的 Hash分配策略)
笔记
以上实现目的是为了突破 Tomcat 接收压力瓶颈问题 , 从而选举优化方案!
# JVM进程缓存
JVM缓存通过Caffeine实现 , 基于Java8 , 使用方式和HashMap一样 , 提供缓存访问 , 可防止库击穿
GitHub地址 : https://github.com/ben-manes/caffeine (opens new window)
JVM缓存的存在意义
可防止同一时间内 , 以最小缓存 , 实现最高性能 , 一定要设置驱逐策略(删除)
对象构造选项
| 链式方法 | 说明 |
|---|---|
maximumSize() | 最大缓存量(key数量) |
expireAfterWrite() | 缓存超时过期时长 |
initialCapacity() | 初始化缓存量(key数量) |
缓存清除策略
一般在构建缓存对象时候 , 指定 过期时间 / 容量上限 删除策略 , 一般采用过期时间 , GC垃圾回收就不用指望了~
思路 : 先实现集群中的JVM缓存 , 通过OpenResty对URI进行哈希运算 , 采用哈希值抉择集群中的主机 , 从而实现同一请求同一主机 , 快速响应 , 从而提高性能 !
应用 :
JVM缓存代码示例 点击展开
依赖
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
@Test
void testBasicOps() {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("name", "Sans");
// 取数据,不存在则返回null
String name = cache.getIfPresent("name");
System.out.println("name = " + name);
// 取数据,不存在则去数据库查询
String defaultGF = cache.get("name", key -> {
// 这里可以去数据库根据 key查询value
return "张三";
});
System.out.println("defaultGF = " + defaultGF);
}
# 多级缓存
OpenResty 共享字典缓存 : 传送门跳转
# 同步缓存
通过 Canal 同步缓存 : 传送门跳转
缓存同步策略
缓存数据同步的常见方式有三种:
设置有效期
给缓存设置有效期 , 到期后自动删除 , 直到再次查询时更新
同步双写
在修改数据库的同时,直接修改缓存
异步通知
修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
区别 :
| 有效期 | 同步双写 | 异步通知 | |
|---|---|---|---|
| 优点 | 简单 , 直接 | 数据时效性强 | 低耦合 , 通知多个缓存 |
| 缺点 | 数据时效性差(过期前) | 耦合性高 | 时效性一般 , 服务状态不一致 |
| 场景 | 更新频率低 , 时效性要求低 | 对一致性 , 时效性敏感 | 一般 , 有多个服务需要同步 |
# Redisson应用
回顾 以往实现的SETNX存在诸多问题
SETNX问题
重写问题 : 同一线程 , 无法多次获取同一把锁
不可重试 : 线程获取锁只能一次尝试 , 没有重试机制
超时释放 : 锁的过期 过短 , 存在线程安全问题 ; 太长 , 存在阻塞情况(左右为难)
主从不一致 : 主从集群情况下 , 同步有延迟 , 当写数据加锁 , 主未同步完从数据 , 主宕机了且业务又没完成 , 那么很有可能出现死锁 , 只能无奈等锁过期~
因此需要一个成熟的框架Redisson去实现逻辑
Redisson是 Redis基础上实现分布式工具框架 , 底层的通过Lua脚本实现 , 分布式场景各种各样的工具均可实现
Redisson提供了一下分布式工具服务 :
- 可重入锁
- 公平锁
- 联锁
- 红锁
- 读写锁
- 闭锁
- ...
官方 : https://redisson.org (opens new window)
GitHub : https://github.com/redisson/redisson (opens new window)
个人笔记应用 : 传送门
# 可重入锁
可重入锁 是 在一个业务方法中调用了其他业务 , 且该业务也存在锁 , 可以理解为锁中锁 .
在Session中 可重入锁 value采用Hash结构存储 , field(Hash中的key)和value 它们分别是 当前线程标识 和 锁的层级(嵌套有多少层) . 每获取一次锁都会自增1(锁层级)
提示
获取锁和释放锁 , 不管在那个业务它们都是成对出现的 !
可重入锁代码示例 点击展开
@Resource
private RedissonClient redissonClient;
@Test
public void business1() {
RLock lock = redissonClient.getLock("lock:"+66);
if (!lock.tryLock()) throw new RuntimeException("确保是自己的锁");
try {
log.info("1. 获取锁 成功");
business2(lock);
} finally {
log.info("1. 释放锁");
lock.unlock();
}
}
public void business2(RLock lock) {
if (!lock.tryLock()) throw new RuntimeException("确保是自己的锁");
try {
log.info("2. 获取锁 成功");
} finally {
log.info("2. 释放锁");
lock.unlock();
}
}
PS : 断点观察锁中的Hash变化情况~
# 获取锁
视频学习 : 详细学习 (opens new window)
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
| 参数 | 说明 |
|---|---|
| KEYS[1] | 锁名称 |
| ARGV[1] | 锁失效时间 |
| ARGV[2] | 线程标识threadId:id |
lua脚本
传参就说明到此 , Redis命令 细品
# 释放锁
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;"
| 参数 | 说明 |
|---|---|
| KEYS[1] | 锁名称 |
| KEYS[2] | 频道名称(用于订阅通知) |
| ARGV[1] | 频道消息 |
| ARGV[2] | 锁失效时间 |
| ARGV[3] | 线程标识threadId:id |
# 分布式锁流程
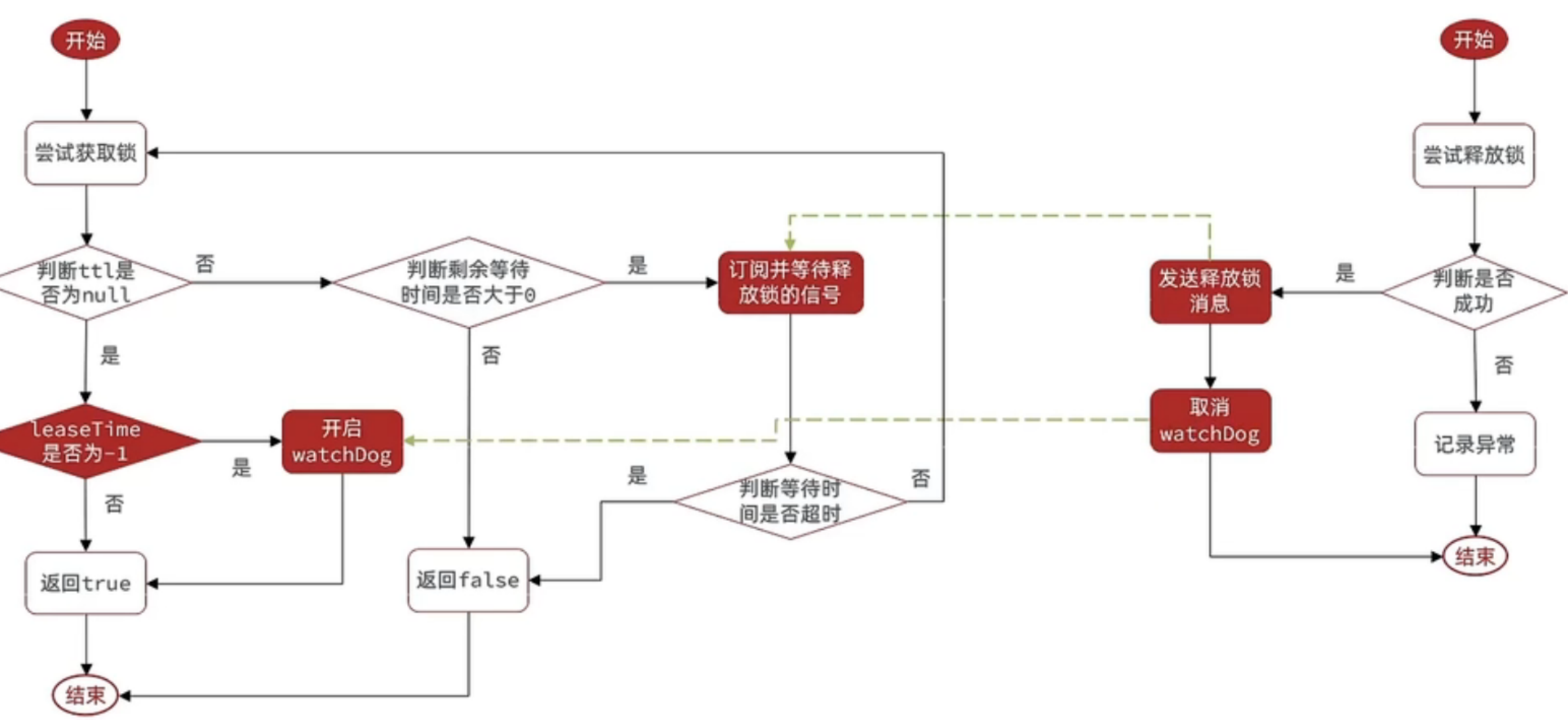
# 集群分布式锁
在企业中为了提高效率 , 一般是已集群Reids主从形式搭建为例子
问题 : 我们有5台Reids服务器 , 一台主(写) 四台从(读取) , 当更改数据主会同步从服务器 , 那么这个同步的过程必有可能会存在延迟 , 如果获取锁时主服务器在同步中途突然宕机了 , 因此我们这个锁可能就失效 , 因此可能还存在隐患 !
解决思路 : 将2台设为主服务器 , 3台设为从服务器 , 以防其中一台主服务器宕机导致锁失效的情况
Java实现
@Configuration
public class ReidssonConfig {
@Bean
@Primary
public RedissonClient redissonClient1() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
// 创建 RedissonClient
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient2() {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6380");
// 创建 RedissonClient
return Redisson.create(config);
}
// 剩下3台代码一样
}
测试
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest
@Slf4j
public class RedissonTest {
@Resource
private RedissonClient redissonClient1;
@Resource
private RedissonClient redissonClient2;
@Resource
private RedissonClient redissonClient3;
@Resource
private RedissonClient redissonClient4;
@Resource
private RedissonClient redissonClient5;
RLock lock;
@Test
public void business1() {
//lock = redissonClient.getLock("lock:"+66);
RLock lock1 = redissonClient1.getLock("lock:"+66);
RLock lock2 = redissonClient2.getLock("lock:"+66);
RLock lock3 = redissonClient3.getLock("lock:"+66);
RLock lock4 = redissonClient4.getLock("lock:"+66);
RLock lock5 = redissonClient5.getLock("lock:"+66);
// 连锁
lock = redissonClient.getMultiLock(lock1, lock2, lock3, lock4, lock5);
if (!lock.tryLock()) throw new RuntimeException("确保是自己的锁");
try {
log.info("1. 获取锁 成功");
business2();
} finally {
log.info("1. 释放锁");
lock.unlock();
}
}
public void business2() {
if (!lock.tryLock()) throw new RuntimeException("确保是自己的锁");
try {
log.info("2. 获取锁 成功");
} finally {
log.info("2. 释放锁");
lock.unlock();
}
}
}
加锁原理
Redisson通过 MutiLock锁 为多个主服务器发送加锁 , 并且这些服务器有原子性的操作
# 布隆过滤器
布隆过滤器能够在海量数据中快速判断一个元素是否包含在一个集合中 . 在实际场景中能够减轻Redis无效交互的负担
深入了解 : 点击跳转 (opens new window)
优点 :
- 能够在海量数据快速判断是否包含指定元素
- 布隆过滤器存储的空间小 , 存储并非对象本身 , 而是对象的 hash结果取模作为标记
- 不存储数据本身 , 适合保密
缺点 :
- 不存数据本身 , 删除数据后 , 存在误判率
- hash碰撞问题 (过滤器匹配存在 , 而缓存中却不存在)
- 容量快慢时 , hash碰撞率变高
根据以上可以得知 只要过滤器匹配不存在则一定会不存在 , 那么过滤器匹配存在则有可能不存在(概率性) , 只要在使用前配置好参数 , 能在一定程度避免无效的Redis交互
以下采用Redisson自带有布隆过滤器实现
简单示例
// 会在Redis创建 filter为key的缓存
public static final RBloomFilter<Object> filter = RedisUtils.getClient().getBloomFilter("filter");
static {
// 初始化过滤器 , 将配置以及空间在Redis创建
filter.tryInit(1000, 0.01);
}
// 布隆过滤
@GetMapping("/t9/get/{id}")
public R<String> test09Get(@PathVariable Long id) {
String key = "test9" + id;
// 过滤不存在的数据
if (!filter.contains(key)) return R.fail("不存在");
// 介入 Redis查询
Object cacheObject = RedisUtils.getCacheObject(key);
if (ObjectUtil.isNull(cacheObject)) return R.fail("不存在");
return R.ok(cacheObject.toString());
}
@GetMapping("/t9/put/{id}")
public R<String> test09Put(@PathVariable Long id) {
String key = "test9" + id;
RedisUtils.setCacheObject(key, id);
filter.add(key);
return R.ok();
}
# 实战技巧
# Key设计
Redis的Key是自定义设计的 , 最好遵循以下约定 :
- 格式 :
<项目名>:<业务名>:<数据>:<id> - 长度不超 44字节
- 不能包含特殊字符
例子 :
login:user:10 , 用户登录业务 , 用户信息
注意
- 格式并非固定 , 可根据业务需求情况而变
- key一定要有个过期时间
# Value结构设计
Redis的Value是根据业务需求场景设计 , 最好遵循以下约定 :
- 合理拆分数据 , 避免 BigKey (集合大数据)
- 选择合适的数据结构
- Hash 数量 建议少于 1k
- 合理设置超时过期时间
BigKey 较大可能导致情况
- 数据倾斜
- CPU压力
- 网络阻塞
- Redis阻塞
发现较大的key :
- 通过命令
redis-cli --bigkeys - scan扫描
- 第三方工具 RDB分析
- 网络监控
假如 有hash类型的key , 当中有 100万 对 键值对 , 如何进行拆分优化?
方案 1 : 拆分 String类型 , 通过JSON转化实现
方案 2 : 拆分 小hash , 根据 id/100 作为 key , 根据 id%100 作为 field , 这样能保证每个小Hash都包含有100个元素
# 批处理
# 批量存数据
批量存数据有多种方案 :
MSET/HMSET命令批量存储- Pipeline 管道存储
MSET命令存储
减少连接次数 , 发送一条命令多个键值对 , 从而实现快速存数据
特点 :
- 只能存String数据
- 占用带宽大 , 容易阻塞
代码示例 点击展开
public static Jedis jedis;
static {
// 连接基本配置 (认证;选择库)
jedis = new Jedis("xxx", 6379);
jedis.auth("xxx");
jedis.select(2);
}
@Test
public void msetTest() {
String[] arr = new String[2000];
int j;
long op = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
// 左位移一位 , 保证对低位为0 , 结果永远是偶数位
// 原理 : 2(1*2) , 4(2*2) , 6(3*2) , 8(4*2) , ... , 0(0*2) (i取余为0)
j = (i % 1000) << 1;
// key和value 是为一对
arr[j] = "test:key_" + i;
arr[j + 1] = "value_" + i;
if (j == 0) {
jedis.mset(arr);
}
}
// 耗时: 5947ms (云服务器)
System.out.println("耗时: " + (System.currentTimeMillis() - op) + "ms");
}
Pipeline
通过管道形式发送 , 多条命令发送
特点 :
- 任意命令组合
- 不具备原子性
代码示例 点击展开
// jedis连接 上面有 就不多写了
@Test
public void pipelineTest() {
// 创建管道
Pipeline pipelined = jedis.pipelined();
long op = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
// 将命令放入管道中
pipelined.set("test:key_" + i, "value_" + i);
// 每1000条 , 发送管道发送一次
if (i % 1000 == 0) {
pipelined.sync();
}
}
// 耗时: 5829ms
System.out.println("耗时: " + (System.currentTimeMillis() - op) + "ms");
}
# 集群批处理
问题 : Redis集群 key会根据 hash值 取余 寻找插槽 , 如果多条命令跑去不同的主机上 , 从而导致执行失败
了解集群插槽机制 : 传送门跳转
解决方案 :
- 批处理必须落在一个slot上
- 分组且每组落在一个slot上
- 采用SpringBoot封装的RedisTemp类(解决了插槽问题)
| 思路 | 优点 | 缺点 | |
|---|---|---|---|
| 串行命令 | for循环 , 每次发送执行一条命令 | 简单 | 耗时大 |
| 串行slot | 计算每个key , 将 hash取余值归类分组 , 根据归类分组存slot , Pipeline进行批处理 , 串行执行各组命令(每组区分不同主机) | 耗时较短 | 实现复杂度高 , slot越多越久 |
| 并行slot | 计算每个key , 将 hash取余值归类分组 , 根据归类分组存slot , Pipeline进行批处理 , 并行执行各组命令 | 非常短 | 实现复杂度高 |
| hash_tag | 将所有key设置相同 {hash_tag} , 规定所有key到指定slot上 , Pipeline进行批处理 | 非常短 | 实现复杂度高 |
| 分组hash_tag | 将所有key设置相同 {hash_tag} , 管道分组设定 hash_tag值 , Pipeline进行批处理 | 非常短 | 实现复杂度高 |
计算Key所对应的slot
ClusterSlotHashUtil.calculateSlot(key)
# Redis 模拟百万数据
- 库插入百万条数据
- redis存储定时10s过期
- 循环刷新测试用时
见的速度
# 服务端优化
# 持久化优化
Redis的持久化虽然可以保证数据安全 , 但也会带来很多额外的开销 , 因此持久化请遵循下列建议 :
- 用缓存的Redis实例尽可能关闭持久化功能
- 关闭 RDB , 启用 AOF (RDB有数据安全隐患)
- 合理设置 rewrite阈值 , 避免频繁 bgrewrite (控制重写频率)
- 配置
no-appendfsync-on-rewrite = yes, 禁止在重写期间做AOF (可能阻塞) - 利用定期脚本在 slave 做RDB备份 (最后稻草)
# 慢查询
Redis执行耗时到达某个阈值的命令 , 称为 慢查询
问题 : Reids收到客户端命令 , 如果执行到慢查询命令 , 后面的其他命令将会在队列等待 慢查询完毕 , 从而导致阻塞情况
解决思路 : 根据日志得知命令的执行时长 , 按业务情况自行优化
Redis根目录下的 redis.conf文件
# 慢查询阈值 , 单位微秒 (默认是10000 ; 建议1000)
slowlog-log-slower-than 1000
# 慢查询日志的上限长度 (默认是128 ; 建议1000)
slowlog-max-len 1000
提示
1秒 = 1000毫秒 = 1 000 000微秒
查看慢查询命令 :
| 命令 | 说明 |
|---|---|
| slowlog len | 查看慢查询日志长度 |
| slowlog get num | 查询第num条慢查询日志 |
| slowlog resset | 清空慢查询列表 |
测试慢查询 :
- 进入 Redis命令终端
- 执行
keys *(一般情况会较慢) - 查看 慢查询日志列表
slowlog len(第一个肯定是) - 查看 指定慢查询列表的命令
slowlog get 1
127.0.0.1:6379> slowlog get 1
# 日志编号
1) 1) (integer) 1
# 日志时间戳
2) (integer) 1680750734
# 慢查询耗时
3) (integer) 67408
# 慢查询命令
4) 1) "keys"
2) "*"
# 执行 IP:Port
5) "127.0.0.1:39334"
# 客户端名称
6) ""
# 安全配置
问题 : Redis绑定在 0.0.0.0:6379 , 这样的服务器暴露在公网 , 很有容易出现漏洞!
漏洞重现方式 : https://cloud.tencent.com/developer/article/1039000 (opens new window)
引起漏洞的主要原因
- Redis未设置密码
- 利用 Redis的
config set命令 动态修改配置 - 利用 Redis账号权限登录Redis
安全设施 :
- Redis设置密码
- 配置
rename-command: 禁止指令 :keys/flushall/flushdb/config set等 命令 - 配置
bind: 限制网卡 , 禁止外网网卡访问 - 服务器 启动防火墙
- 尽可能避免Root启用Redis
- 尽可能不使用默认端口
# 内存配置
问题 : 内存利用不当 , 很容易导致内存不足现象 , 可能导致 key误删/响应变长/QPS不稳定 等问题 .
快速定位原因 :
数据内存 存储了BigKey , 内存碎片
进程内存
Redis主进程本身内存 , 一般是忽略不计
缓冲区内存
缓冲区/AOF缓冲区/复制缓冲区 等 . 主要源于 客户端连接操作影响的内存波动
# 缓存预存储
按照不同场景进行提前缓存数据
意义 : 降低服务器压力
注意
- 缓存空间不能太大 , 预留其他缓存
- 缓存数据周期 控制失效时间
# 定时触发
场景 : 定时每天为用户推送列表/
方案 :
- Spring Scheduler (Spring boot 内置)
- Quartz (独立框架)
- XXL-Job 分布式任务调度平台 (UI+SDK)
推荐学习 : XXL-Job (opens new window)
# 手动触发
# 工具类
此工具类解决了 : 缓存 击穿/雪崩/穿透 问题 (详细跳转
工具类 展开
@Slf4j
@Component
public class CacheOperation {
private StringRedisTemplate redisTemplate;
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public CacheOperation(StringRedisTemplate stringRedisTemplate) {
this.redisTemplate = stringRedisTemplate;
}
/**
* ttl缓存
*/
public void set(String key, Object value, Long ttl, TimeUnit unit) {
String valJson = JSONUtil.toJsonStr(value);
redisTemplate.opsForValue().set(key, valJson, ttl, unit);
}
/**
* 逻辑过期 缓存
*/
public void setWithLogicalExpire(String key, Object value, Long time, TimeUnit unit) {
RedisData redisData = new RedisData(
value, LocalDateTime.now().plusSeconds(unit.toSeconds(time))
);
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
/**
* 防 击穿缓存
*/
public <R, ID> R findWithPassThrough(
String key, String lockKey, ID id, Class<R> type, Function<ID, R> dbFallback, Long ttl, TimeUnit unit) {
String json = redisTemplate.opsForValue().get(key);
if ("".equals(json)) return null;
if (StrUtil.isNotBlank(json)) return JSONUtil.toBean(json, type);
R r;
try {
// 分布式锁
// 未获取锁重新获取
if (!tryLock(lockKey)) {
Thread.sleep(1000);
return findWithPassThrough(key, lockKey, id, type, dbFallback, ttl, unit);
}
// 查看锁是否存在
String lockStr = redisTemplate.opsForValue().get(lockKey);
if (StrUtil.isEmpty(lockStr)) return findWithPassThrough(key, lockKey, id, type, dbFallback, ttl, unit);
// 查询库
r = dbFallback.apply(id);
if (r == null) {
redisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
this.set(key, r, ttl, unit);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
return r;
}
/**
* 逻辑过期缓存
*/
public <R, ID> R findByIdWithLogicalExpire(String key, String lockKey, ID id, Class<R> type, Function<ID, R> dbFallback, Long ttl) {
R r;
String json = redisTemplate.opsForValue().get(key);
if ("".equals(json)) return null;
RedisData redisData = JSONUtil.toBean(json, RedisData.class);
// 提取数据
r = JSONUtil.toBean((JSONObject) redisData.getData(), type);
LocalDateTime expiredTime = redisData.getExpiredTime();
// 缓存未过期
// 逻辑过期时间 > 现在时间
if (expiredTime != null && expiredTime.isAfter(LocalDateTime.now())) return r;
// 获取锁 失败 返回旧数据
if (!tryLock(lockKey)) return r;
// 开启 独立线程 , 实现获取库信息
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 库操作前 , 确保信息过期/null
if (expiredTime == null || expiredTime.isBefore(LocalDateTime.now())) {
R bean = dbFallback.apply(id);
// 控制逻辑过期时长 . 可选时间单位 (为了方便测试将时间单位设为s)
RedisData redisDataTemp = new RedisData(bean, LocalDateTime.now().plusSeconds(ttl));
// 写入
redisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisDataTemp));
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
});
return r;
}
// 建立锁
public boolean tryLock(String key) {
Boolean flag = redisTemplate.opsForValue().setIfAbsent(key, "1", LOCK_SHOP_TTL, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// 删除锁
public boolean unLock(String key) {
Boolean flag = redisTemplate.delete(key);
return BooleanUtil.isTrue(flag);
}
}
# 队列工具
# Q&A
# 缓存问题
缓存是在第一次加载的数据进行复用,将数据存放指定地点以便下次加载使用。可防止多访问同一 数据库 而产生的堵塞,也能减轻 数据库 的压力!
Java缓存
- 虚拟机缓存(ehcache、JBoss Cache)
- 分布式缓存(redis、memcache)
- 数据库缓存
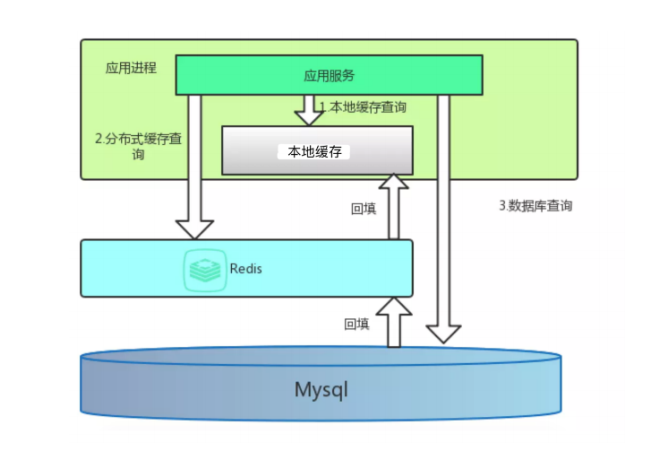
# 缓存雪崩
当 Reids宕机/同一时间key失效 , 所导致的大量请求数据库 , 会对数据库造成巨大压力从而宕机
解决方案 :
- 为不同key , 设置随机TTL值(控制范围)
- 集群搭建Redis
- 熔断/降级/限流 控制流量
# 缓存穿透
当用户查询特定数据时 , 发现缓存和数据库中都没有数据 , 并且继续访问该数据 , 会导致访问数据库进行查询操作 , 那么长时间这样操作 , 可能会导致数据库宕机 . 这种情况就是直接绕过缓存 , 直接访问数据库
解决方案 :
缓存空对象 , 把在数据库查询的null进行缓存并设置TTL , 那么频繁的访问就不会直接到达数据库的目的
缺点 : 占用一定内存 ; 造成短期数据不一致问题
优化
- 对id增强复杂度 , 避免规律id猜测问题
- 对数据进行校验 , 防止不规数据乱入
- 布隆过滤
# 缓存击穿
在某一段时间 出现超高并发访问 , 如果缓存key数据 (热点数据) 即将过期 , 在过期的一瞬间可能会导致大量数据共同访问数据库
解决方案 :
- 互斥锁 (又称分布式锁)
- 逻辑过期
互斥锁 (分布式锁)
设置个分布式锁 , 当多个请求同时访问 , 只允许第一个访问的请求 , 那么其他请求将会等待
优点 : 节省内存 ; 保证数据一致 ; 实现简单
缺点 : 线程等待 , 信息时效性差 ; 死锁风险
互斥锁代码示例 展开
思路 : 通过Redis中的 SETNX命令特性实现分布式锁 ! 实现同一时间多个请求只允许一个访问
创建分布式锁控制方法
// 建立锁
public boolean tryLock(String key) {
Boolean flag = redisTemplate.opsForValue().setIfAbsent(key, "1", 30, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// 删除锁
public boolean unLock(String key) {
Boolean flag = redisTemplate.delete(key);
return BooleanUtil.isTrue(flag);
}
逻辑方法 , 加锁约束
public Bean findByIdWithLock(Long id) {
String key = "sans:test:" + id;
String lockKey = "sans:lock:" + id;
Bean bean;
try {
String beanJson = redisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(beanJson)) return JSONUtil.toBean(beanJson, Bean.class);
// 分布式锁
// 未获取锁重新获取
if (!tryLock(lockKey)) {
Thread.sleep(1000);
return findByIdWithLock(id);
}
// 查看锁是否存在
String lockStr = redisTemplate.opsForValue().get(lockKey);
if (StrUtil.isEmpty(lockStr)) return findByIdWithLock(id);
// 查库
bean = this.getById(id);
// 缓存
if (bean == null) throw new RuntimeException("不存在");
redisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(bean), 10, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 释放锁
unLock(lockKey);
}
return bean;
}
测试 : 同一时间发多个请求 , 分别测试 开启/关闭 分布式锁 两种情况
- 开启 : 数据库只会查一次
- 关闭 : 数据库可能会插一次以上
逻辑过期
key数据不设置TTL过期时间 , 而是在value中设置过期时间 , 通过检测value进行判断过期时间
优点 : 线程无需等待 , 性能好
缺点 : 数据不一致(旧数据返回) ; 消耗内存 ; 实现复杂
流程步骤图 点击展开
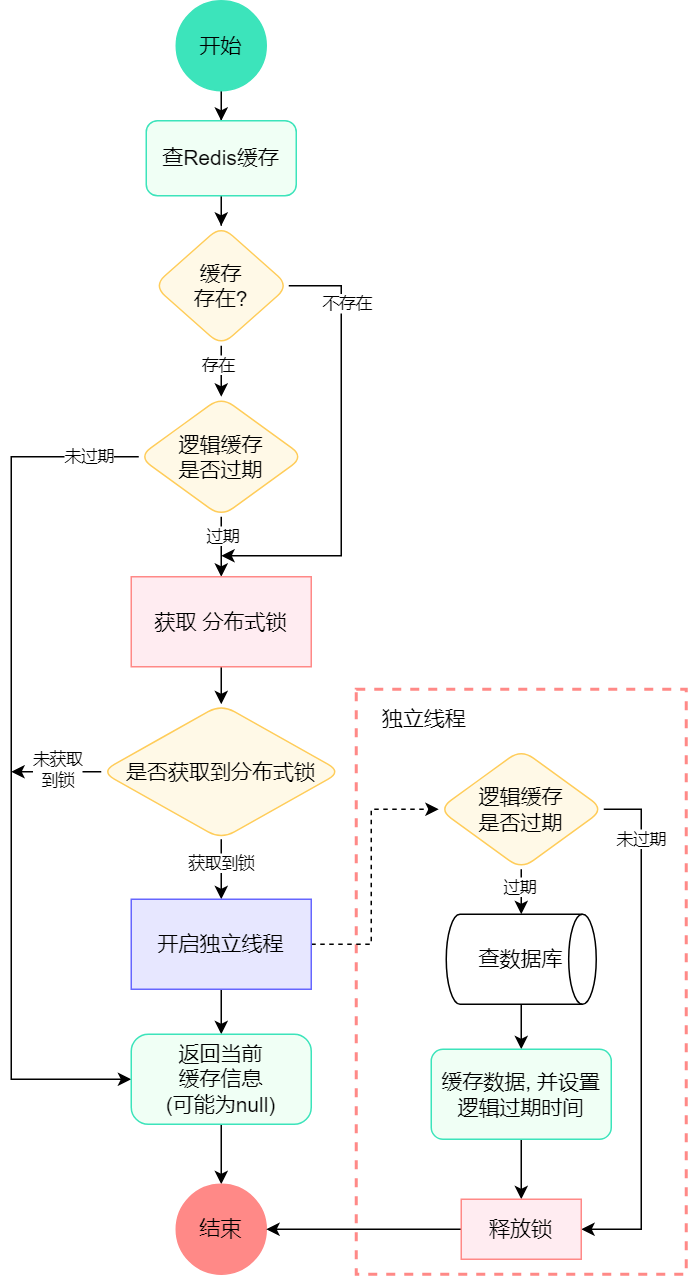
逻辑过期 代码示例 展开
思路 : 通过value存过期时间 , 通过过期时间判断是否更新 , 未过期则返回旧数据
库查询 缓存存储部分
public void saveToRedis(Long id, Long expired) throws InterruptedException {
Bean bean = this.getById(id);
// 为了更能体现出数据库正在查询数据 , 而营造的延迟
Thread.sleep(1000);
RedisData redisData = new RedisData(bean, LocalDateTime.now().plusSeconds(expired));
// 写入
redisTemplate.opsForValue().set("sans:cache:bean:"+id, JSONUtil.toJsonStr(redisData));
}
RedisData对象结构
@Data
public class RedisData {
private LocalDateTime expiredTime;
private Object data;
public RedisData() {
}
public RedisData(Object data, LocalDateTime expiredTime) {
this.expiredTime = expiredTime;
this.data = data;
}
}
分布式锁
// 建立锁
public boolean tryLock(String key) {
Boolean flag = redisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// 删除锁
public boolean unLock(String key) {
Boolean flag = redisTemplate.delete(key);
return BooleanUtil.isTrue(flag);
}
主业务部分
// 独立线程池
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
// Bean 实体对象
private Bean findByIdWithLogicalExpire(Long id) {
String key = "sans:cache:bean:" + id;
String lockKey = "sans:lock:bean:" + id;
Bean bean;
String beanJson = redisTemplate.opsForValue().get(key);
if ("".equals(beanJson)) throw new BusinessException("不存在了!");
RedisData redisData = JSONUtil.toBean(beanJson, RedisData.class);
// 提取数据
bean = JSONUtil.toBean((JSONObject) redisData.getData(), Bean.class);
LocalDateTime expiredTime = redisData.getExpiredTime();
// 缓存未过期
// 逻辑过期时间 > 现在时间
if (expiredTime != null && expiredTime.isAfter(LocalDateTime.now())) return bean;
// 获取锁 失败 返回旧数据
if (!tryLock(lockKey)) return bean;
// 开启 独立线程 , 实现获取库信息
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 库操作前 , 确保信息过期/null
if (expiredTime == null || expiredTime.isBefore(LocalDateTime.now())) {
this.saveToRedis(id, 10);
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
});
return bean;
}
测试 :
以下我设定了逻辑过期时间为10s , 等待到第9s时 , 多次发数据可观察数据变化情况 (主要是步骤的思路 , 不多BB)
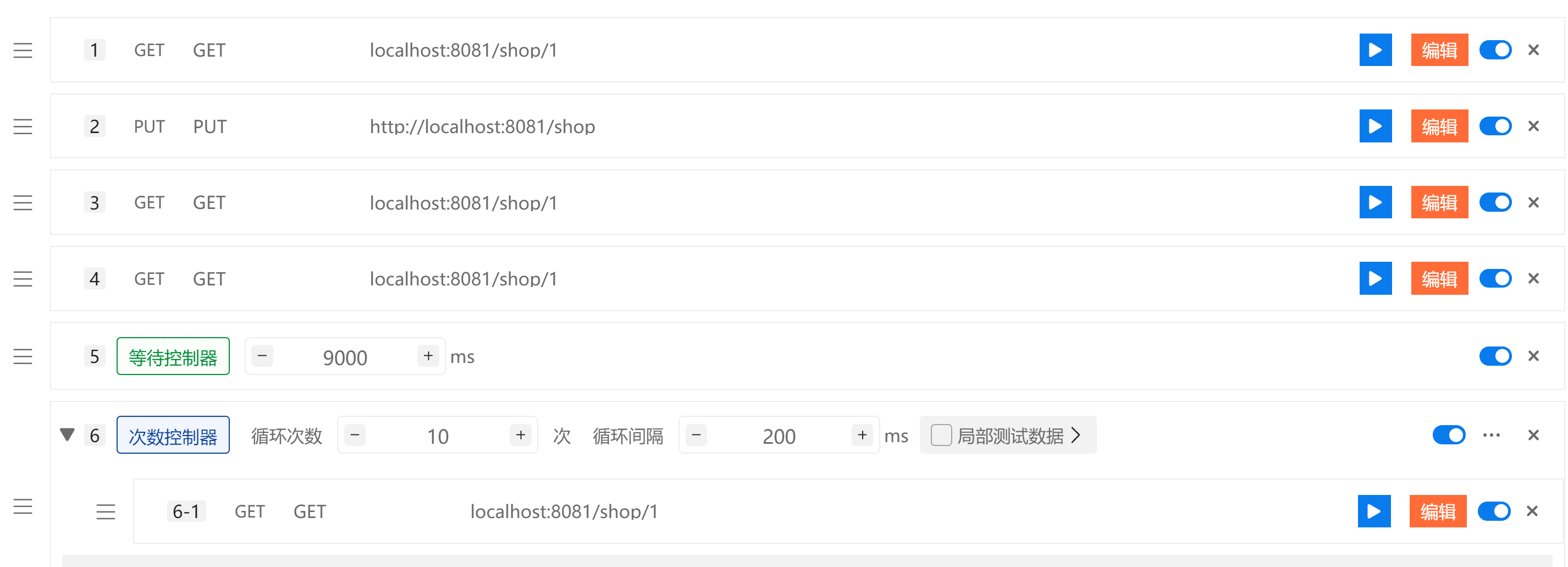
提示
虽然有些许复杂 , 但是思路非常棒!
# 分布式锁问题
# 死锁
Q : setnx命令 , 未释放资源
A :
- 设值过期
- 关闭锁
# JVM锁和分布式锁
| JVM锁 | 分布式锁 | |
|---|---|---|
| 锁范围 | JVM中的多线程 | 多个JVM |
| 实现于 | Java | Redis/MySQL/Zookeeper/等 |
JVM应用的范围过于局限 , 因此需要分布式扩大锁的范围
# 续约锁
Q : 如果锁所执行的方法时间过长 , 锁提前过期 , 导致他人占用?
A : 续约锁的时长进行加时
续约锁的目的主要是防止锁长时间占用问题 , 达到节省资源
Q2 : 释放锁的时候 , 先前判断出是自己的锁 , 由于执行时间过长导致期间锁过期了 , 此时被其他节点所占用 , 因此方法很有可能会将别的节点锁进行释放! (以下伪代码示例)
// 此时判断为A锁含有过期
if(get lock == A){
// 执行过程....(漫长
del lock; // 释放锁(此时锁可能不为A)
}
A2 : Redis + lua脚本 实现